


Navigating the Complexities of Generative AI Implementation: A Strategic Guide for Tech Leaders+

Generative AI, often referred to as GenAI, has become a pervasive force across industries, prompting organizations to vie for a competitive edge. Yet, the journey to building a generative AI model that genuinely enhances business value is a formidable challenge. While a hasty integration with the OpenAI API might seem like progress, the absence of a distinctive advantage over platforms like ChatGPT is a critical concern.
In this ever-evolving landscape, akin to the race between Blockbusters and Netflixes, tech leaders find themselves at a crossroads. If your team is still engaged in preliminary discussions about “bubbles” and “hype,” it’s imperative to confront some stark realities, unraveling the complexities that lie beneath the surface.
1. Adoption Hurdles and Monetization Delays:
The struggle for adoption and the sluggish pace of monetization are often symptoms of an AI initiative that hasn’t been calibrated to address well-defined user problems. However, as user needs evolve, integrating GenAI to solve specific issues will likely lead to more substantial adoption. The secret sauce? The integration of high-quality proprietary data, transforming GenAI features from mere novelties to indispensable tools.
2. Overcoming the Fear of Expanding Gen AI Usage:
The realm of generative AI can be intimidating, particularly when contemplating a more profound integration into organizational processes. Concerns about risks, unpredictability, and potential legal ramifications can create a barrier to progress. However, steering clear of the playing field won’t resolve these issues. It’s imperative to understand the intricacies of the data being fed into GenAI and ensure its accuracy for meaningful results.
3. Untangling the Complexity of Retrieval Augmented Generation (RAG):
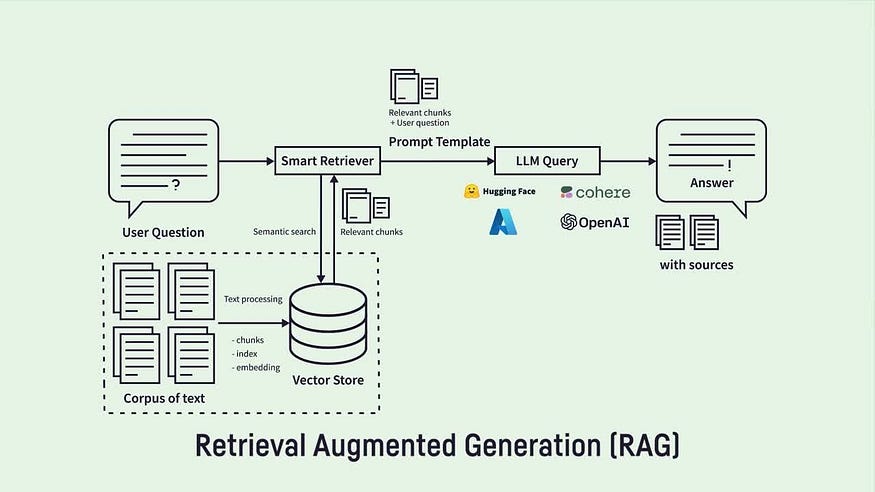
While RAG stands as a linchpin for the future of enterprise generative AI, the development process is intricate. Data engineers find themselves navigating the complexities of prompt engineering, vector databases, embedding vectors, and orchestrating data pipelines. RAG applications, by grounding models in proprietary data, make the entire ecosystem more valuable and dynamic.
4. Assessing Data Infrastructure Readiness:
Even with a seemingly perfect RAG pipeline, a finely tuned model, and a clearly defined use case, the readiness of your data infrastructure is a critical factor often overlooked. Comprehensive and well-modeled datasets are foundational for effective GenAI implementation. If your data isn’t prepared, your GenAI initiative might be a year or more away from realization.
5. Recognizing the Importance of Critical Gen AI Players:
GenAI development is a collaborative endeavor, and overlooking key players, especially data engineers, can be a costly misstep. Data engineers play a pivotal role in comprehending proprietary business data, providing a competitive edge, and constructing pipelines for seamless data accessibility.
Achieving victory in the GenAI race necessitates a strategic recalibration. Understanding evolving customer needs, involving data engineers from the project’s inception, constructing a robust RAG pipeline, and investing in a modern data stack to prioritize data quality are indispensable steps. Without a foundation of high-quality data, generative AI remains an ephemeral promise.
In the dynamic and multifaceted landscape of generative AI, confronting these stark truths becomes the linchpin for building a resilient, impactful, and successful GenAI strategy.
The link to the WhatsApp community becomes the portal where GrowGlobal and tech leaders converge, sharing insights and strategies amidst the cosmic echoes of innovation. In this celestial odyssey, only those with the heart of heroes and the alliance with GrowGlobal will stand triumphant, shaping the future landscapes of the digital universe.
🌐 Join the GrowGlobal WhatsApp Community and become part of the digital saga!











